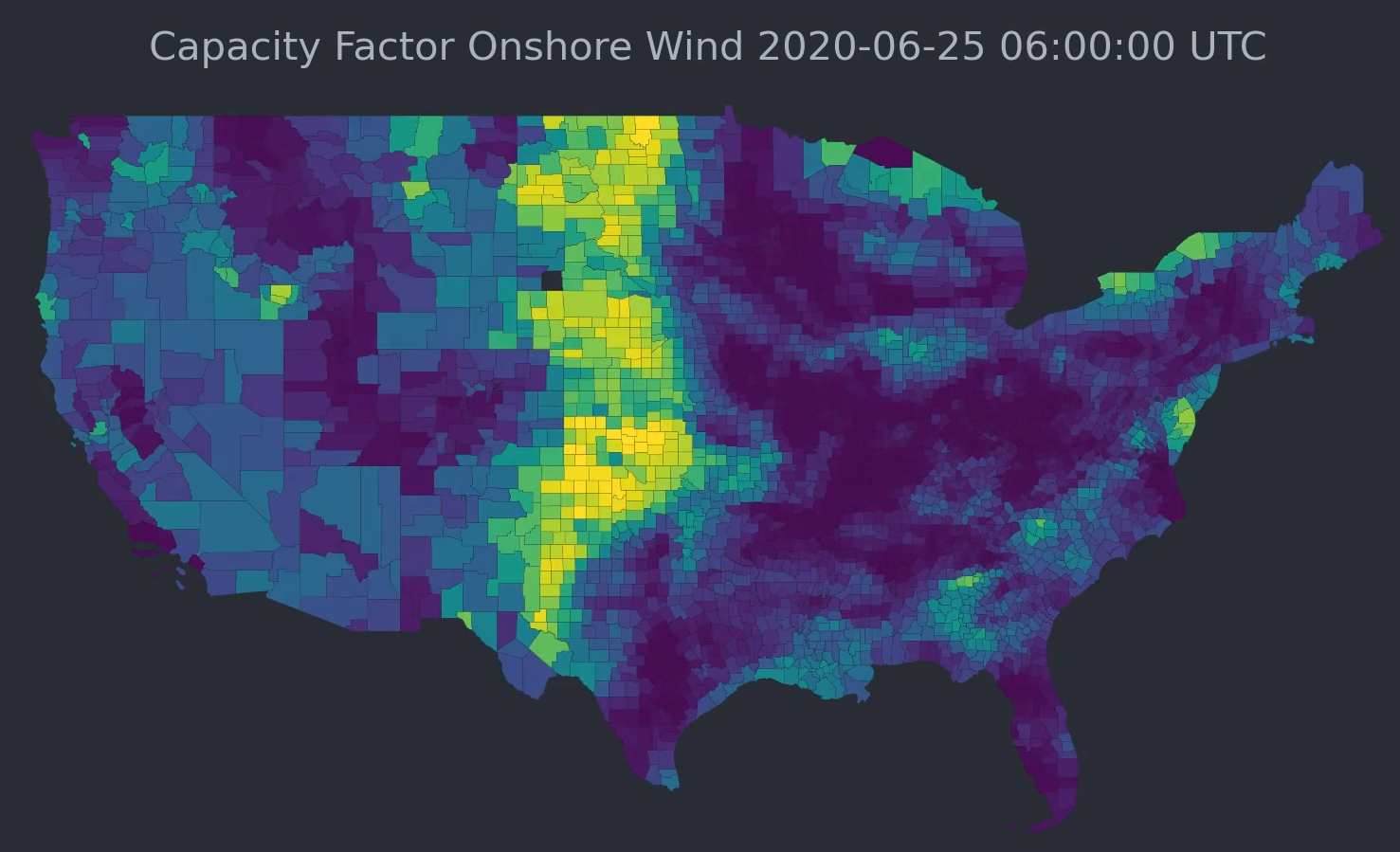
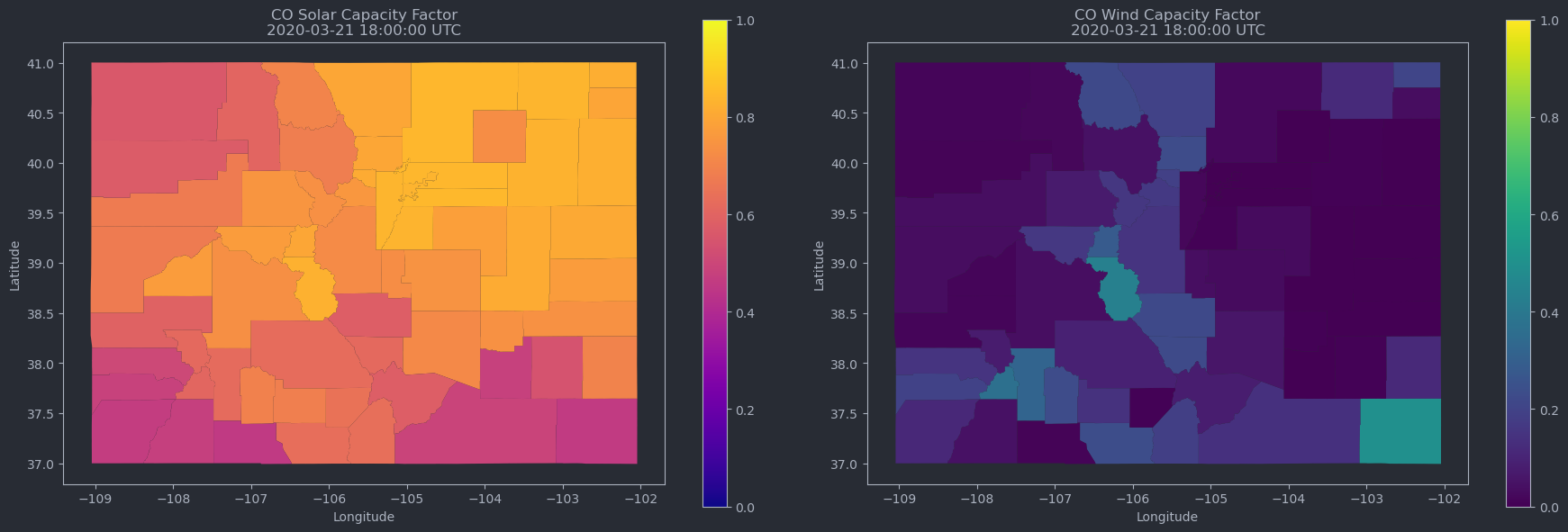
We’re excited to be part of the Mozilla Technology Fund’s 2024 cohort, which is focusing on open source AI for environmental justice!
We’re going to use Mozilla’s support to link US Securities and Exchange Commission data about utility ownership to financial and operational information in the EIA forms 860/861/923, and through our previous record linkage work involving the EIA data, to FERC Form 1 respondents and the EPA’s continuous emissions monitoring system data.
The SEC Form 10-K is published through EDGAR as structured XBRL data, but the Exhibit 21 attachment that describes which companies own and are owned by other companies is unfortunately just a PDF blob that gets stapled to the XBRL, and so ownership relationships end up being unstructured, or at best, semi-structured data.
We’re going to apply document modeling tools that we’ve developed in some of our client work (to extract structured data from PUC and other regulatory filings) to extract the ownership information from Exhibit 21. This will hopefully include the ownership percentages when they are reported.
Then we’re going to use the generalized entity matching / record linkage tooling that we developed under our previous Climate Change AI Innovation Grant to connect the parent / subsidiary companies named in the SEC data to the financial and operational data reported by the same utility companies in FERC Form 1, as well as EIA and EPA data.
The record linkage / entity matching system that we’ve ultimately settled on is based on the excellent (and publicly funded!) Splink library, which relies on DuckDB to enable local linkages on datasets of up to tens of millions of records. Robin Linacre (one of the Splink maintainers) has a tutorial explaining the probabilistic model of record linkage used by Splink, if you’re interested in the internals.
Why is this work important? Being able to make effective energy policy often requires an understanding of the political economy of utilities, and utilities are often composed of Russian doll-like nested holding companies. It can be hard to see where one utility ends and another begins. Understanding which entities share ownership and thus political and economic interests is key to being able to grapple with and influence them.
We’ll be learning from prior work on this problem done by the folks at CorpWatch, and we hope to make the outputs of our work easy to visualize and explore through the Oligrapher interface that LittleSis has developed.
If this work is interesting or useful to you, we’d love to hear more about your use case! You can track our work through this GitHub repository. Also, while we are explicitly focused on and familiar with utilities, the SEC’s Form 10-K covers all publicly traded companies, so we may be producing additional data outputs that aren’t useful to us but which could be useful to others. If that’s you, please let us know.