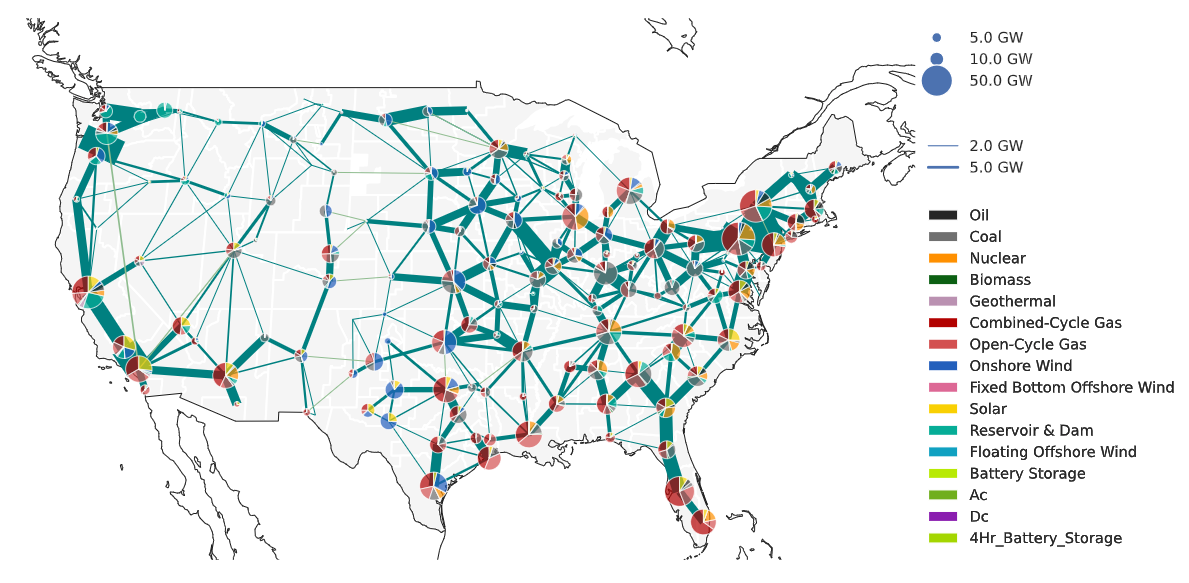

We recently found out that Kamran Tehranchi, one of two primary maintainers of the PyPSA-USA open source power system model, was working on adapting it to use open data that we publish through our Public Utility Data Liberation Project (PUDL), so we interviewed him over email to find out more about his experience making the switch.
Can you tell us a little bit about yourself? What problems are you working on? Where are you at?
Sure! I’m currently a PhD Student at Stanford University working in the Interdisciplinary Energy Systems (INES) Lab. By way of my research, I am also an energy system modeler and open-source software developer. My work focuses on electricity system planning, specifically on the impact of electricity transmission resolution within planning models. I primarily work with engineering-economic simulation and optimization models, mainly production cost simulations and capacity expansion models. I use these models to design and simulate future energy systems to understand the impacts of emerging technologies, policies, and climate-energy system interactions. One of the main projects I’ve been working on this past year is the PyPSA-USA planning model which in-part leverages PUDL to develop the electricity system data model.
Can you tell us a little bit about the PyPSA-USA project? Who are the intended users or target audience? What role does it play in the broader landscape of the energy transition?
Sure, I’ll start with some motivation first. When I began my research on transmission planning in California, I was surprised to learn there was no open-source data-model with suitable transmission resolution available. I needed a model that had more detailed transmission resolution than the popular models which use ~4-6 nodes for California, but not quite so many as the available multi-thousand node network (TAMU). My research question required a medium resolution electricity network between the common zonal planning models and the nodal operational models. PyPSA-USA is a response to this initial problem that I faced and addresses many other aches and pains of energy system modelers. PyPSA-USA helps researchers flexibly design their own energy system models so that can spend less time in data-cleaning and validation, and more time answering interesting questions.
PyPSA-USA is a flexible open-source energy system data-model preparation and optimization tool for the continental United States. There are two main uses-cases for PyPSA-USA:
- First, it can be used to create data-models for the US energy system with high user-configurability. For instance, a user can build networks with zonal or nodal transmission topologies, historical or forecasted demand, and renewable profiles built from decades of climate data. (There are quite a few more configuration options I won’t cover here).
- Second, it solves simulation and optimization models for your custom-built networks. We use the open-source Python for Power System Analysis (PyPSA) package to solve these capacity expansion planning problems and operational simulations. If you’re familiar with the PyPSA-Eur model, we closely follow their workflow as to not reinvent the wheel when it comes to network clustering and optimization formulations.
The primary users of the project so far have been energy system researchers like myself. As the project has matured, I have received inquiries from folks in industry who are interested in replacing their in-house or proprietary capacity expansion model with PyPSA-USA. In the broader energy transition landscape, PyPSA-USA fits alongside other open-source models like GenX, GridPath, and NREL’s ReEDS, in providing researchers and policy makers transparent decision support tools to aid in system planning. We are quickly moving towards a world where regulatory proceedings can use transparent mature open-source software that exceeds the functionality of today’s popular commercial options. Our project is one piece of the puzzle that inches us towards that world.
What input data does PyPSA-USA depend on? Historically where has it come from, and how have you managed it?
The tool integrates data from many different sources, including:
- U.S. Energy Information Administration (EIA)
- National Renewable Energy Laboratory (NREL)
- U.S. Environmental Protection Agency (EPA)
- Western Electricity Coordinating Council (WECC)
- Electric Power Research Institute (EPRI)
- California Independent System Operator (CAISO)
- California Energy Commission (CEC)
- European Centre for Medium Range Weather Forecasts (ECMWF)
- U.S. Bureau of Ocean Energy Management (BOEM)
- Copernicus Land Monitoring Service (CLMS)
We use data from all these sources to populate information on the characteristics of energy infrastructure, both for existing infrastructure, and the expected values for future infrastructure. The characteristics of existing powerplants is one of the most important data-sets. When we got started with the project, we built our workflow to download EIA-860 Excel files, fuel prices assimilated from the EIA API and CAISO’s OASIS platform. We use the python package snakemake to manage the retrieval and pre-processing of these files and their corresponding python-based preprocessing scripts. We now use PUDL as the main source for our existing power plant dataset which helps us maintain continuity of the project as new data is released!
If you’ve considered using PUDL data at some point in the past, and decided not to, what prevented you from using it? What made you decide to switch to using PUDL data as an input into PyPSA-USA?
I considered using PUDL early on, but decided against it until I made more progress on the project. At the time PUDL was missing the EIA 860 energy storage table, and because I would have needed to download those Excel files anyways to get our project off the ground, I decided to move forward using the flat files. At the time PyPSA-USA was young and non-functional, and I needed to make some progress on my research before making contributions back to PUDL to integrate the table I needed.
PyPSA-USA integrated PUDL thanks to the contributions of a software developer in England who learned about our project through a group named Win Climate. He made a pull request to address an existing GitHub issue for the initial PUDL integration, which got us off the ground. I then took what he developed and have been integrating more data from the database ever since!
What has the migration/integration experience been like so far? Have you run into any frustrating issues? Is there anything that’s been particularly great?
The migration experiences has been overall great! I’ve run into some issues in dialing in my queries to synthesize data across the many years of EIA data PUDL has collected. The most useful part of PUDL has been the preparation of fuel receipts data. Originally we were only using EIA and OASIS based wholesale fuel prices, which doesn’t take into account the differences in contracted prices. PUDL has monthly fuel receipts and marginal cost of electricity calculated based on individual plant heat rates. We took this data, performed additional cleaning and assimilated it with our wholesale fuel prices as well. In our back-casting exercises, this additional data made the biggest difference in correcting issues in generation mix across the States.
What are the state-level generation mix issues you’re trying to address? How did adding the fuel receipts and costs data for individual deliveries improve the accuracy of your results? What does backcasting mean in this context?
A key part of developing a new energy system model is validating that the simulated system behaves similarly to the operation of a historical system. To conduct this validation, we run “back-casting” simulations, where we simulate the operations of the electricity system under a historical weather year, and compare the differences between historical and simulated results for key metrics. These metrics include generation production, emissions, and market prices. We will never match the dispatch perfectly because there are so many differences between our models and the real world, but we should see similar behavior.
Fuel costs and heat rates are the main drivers determining which plant will be dispatched before another (aka the merit-order). When we started back-casting with PyPSA-USA, we found that using singular fuel costs per technology type and State, did not provide enough granularity to accurately represent historical operations. PUDL’s fuel receipt data provided plant level fuel prices, which mirrored our state level aggregate data, but provided much higher granularity on intra-state contracted differences. As soon as I integrated this data, our back-casting results greatly improved, and it became clear that intra-state differences fuel costs accounted for a large portion of error in our model.
How would you like to see the relationship between PUDL and PyPSA-USA evolve over time? Are you interested in making open source contributions to PUDL? Are there any additional datasets or outputs that PUDL could integrate or curate that would be particularly helpful to your work?
I can already see PyPSA-USA integrating more data from PUDL (next up is the NREL ATB), and I imagine is more on the way. I have already identified an issue with incorrect plant lat/lon coordinates in PUDL, which I am planning to take on. I could also imagine moving some of the heat-rate and fuel-cost post-processing that I do in PyPSA-USA into PUDL so others can take advantage of the cleaned data.
As to my data wish-list, I think you guys already have the major datasets covered. Maybe the next one would be State, Federal, and Regional energy policies that are often implemented in these models. I go directly to ReEDS for that right now, but it would be great to have it updated in a streamlined fashion without additional flat-files.
We’ve talked to other energy system modelers who have highlighted the need for a programmatically usable, regularly updated representation of state/regional/federal energy policies (especially state). They’ve noted that this can be the largest source of uncertainty in the future scenarios they model. What’s the impact on your work of not having that information?
The lack of a singular reliable source of this data has forced me to spend extra time trying to find and validate this data myself. I currently rely on the NREL ReEDS dataset for the bulk of this information but have noticed some discrepancies in that dataset which required manual updating and validation. This is a tough one to tackle, because each state’s policies have small details to ingest which I believe will take some expertise and manual translation into a modeling friendly framework.
Connect with Kamran:
- On LinkedIn in/kamrantehranchi
- On GitHub: @ktehranchi
- On Twitter: @kaambool